
Introduction
Imagine you’re a data scientist tasked with predicting customer churn for an e-commerce platform. You have heaps of raw data but no clear roadmap. Without a structured machine learning workflow, you could easily get lost in data preprocessing, feature selection, and model tuning. A defined workflow ensures efficiency, clarity, and reproducibility while helping teams avoid common pitfalls.
This guide will break down the entire process from data collection to model deployment, offering actionable tips and real-world examples.
1. Define the Problem and Set Goals
The first and often most overlooked step in any machine learning project is problem definition. A clear understanding of your business or research goal sets the foundation for the entire workflow.
Steps to define the problem
- Identify the objective (e.g., reduce churn, detect fraud, predict sales).
- Define success metrics (accuracy, F1-score, RMSE).
- Determine constraints (time, resources, privacy regulations).
Example: If your goal is to reduce churn, the problem could be framed as a classification task: predicting whether a customer will churn within the next 30 days. Your success metric might be F1-score due to class imbalance.
2. Data Collection
Data is the backbone of any machine learning project. Collecting high-quality, relevant data ensures that your models can learn patterns effectively.
Sources of data
- Internal databases (CRM, sales records)
- Public datasets (Kaggle, UCI Machine Learning Repository)
- APIs (social media analytics, weather data)
- Web scraping (news, e-commerce trends)
Practical Tip: Avoid collecting more data than necessary initially. Focus on high-quality, relevant datasets to save time during preprocessing.
3. Data Preprocessing and Cleaning
Raw data is rarely ready for machine learning. Cleaning and preprocessing are essential to ensure model accuracy and reliability.
Key preprocessing steps
- Handling missing values (imputation, removal)
- Removing duplicates and outliers
- Encoding categorical variables (one-hot encoding, label encoding)
- Feature scaling (normalization, standardization)
Example: In a customer churn dataset, missing age values can be imputed using the median age. Similarly, categorical variables like subscription type should be converted into numerical forms.
Common Data Preprocessing Techniques
| Technique | Purpose | Example |
|---|---|---|
| Imputation | Handle missing values | Median age imputation |
| One-hot encoding | Convert categories to numbers | Subscription type |
| Standardization | Scale features | Z-score normalization |
4. Exploratory Data Analysis (EDA)
EDA helps uncover patterns, trends, and anomalies in your data. It’s a critical step that informs feature selection and engineering.
Techniques
- Descriptive statistics (mean, median, variance)
- Visualizations (histograms, scatter plots, box plots)
- Correlation analysis (Pearson, Spearman)
Example: A correlation heatmap might reveal that customer tenure and monthly charges are highly correlated with churn. This insight can guide feature engineering.
As you explore your data visually and statistically, you’ll often find surprises (skewed distributions, unexpected nulls, collinearity). A good companion read is Kaggle’s Intro to EDA in Python, which walks through common patterns and pitfalls.
5. Feature Engineering and Selection
Feature engineering involves creating new variables that make your model more predictive, while feature selection focuses on choosing the most relevant features.
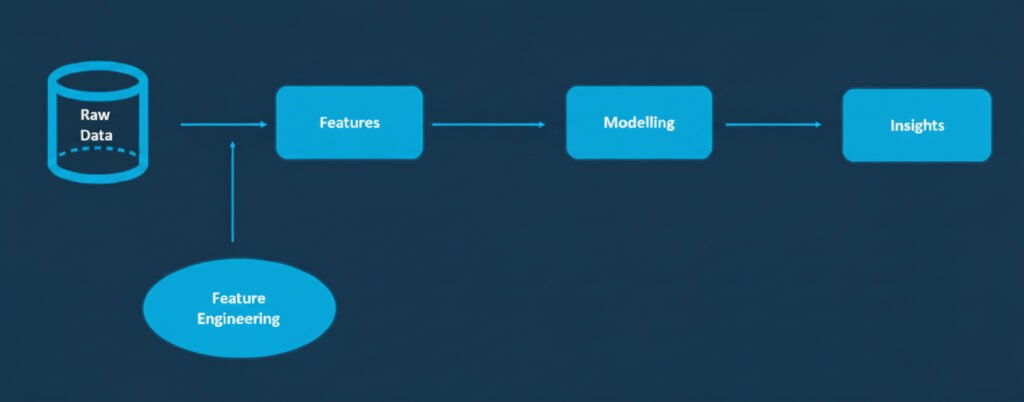
Strategies
- Polynomial features: Capture non-linear relationships.
- Interaction terms: Combine features to create new predictive signals.
- Dimensionality reduction: PCA, LDA, or feature importance ranking.
Example: For predicting sales, combining season and holiday variables might create a powerful feature reflecting holiday-season effects.
“5 Powerful Feature Selection Techniques in Scikit-learn” Medium article — a practical, up-to-date walkthrough of feature selection methods like RFE, L1, variance threshold, etc.
6. Model Selection
Choosing the right algorithm is key to model success. Factors like dataset size, feature type, and problem type influence selection.
Common algorithms
- Classification: Logistic Regression, Random Forest, SVM
- Regression: Linear Regression, Gradient Boosting
- Clustering: K-Means, DBSCAN
- Deep Learning: CNNs for images, LSTMs for sequences
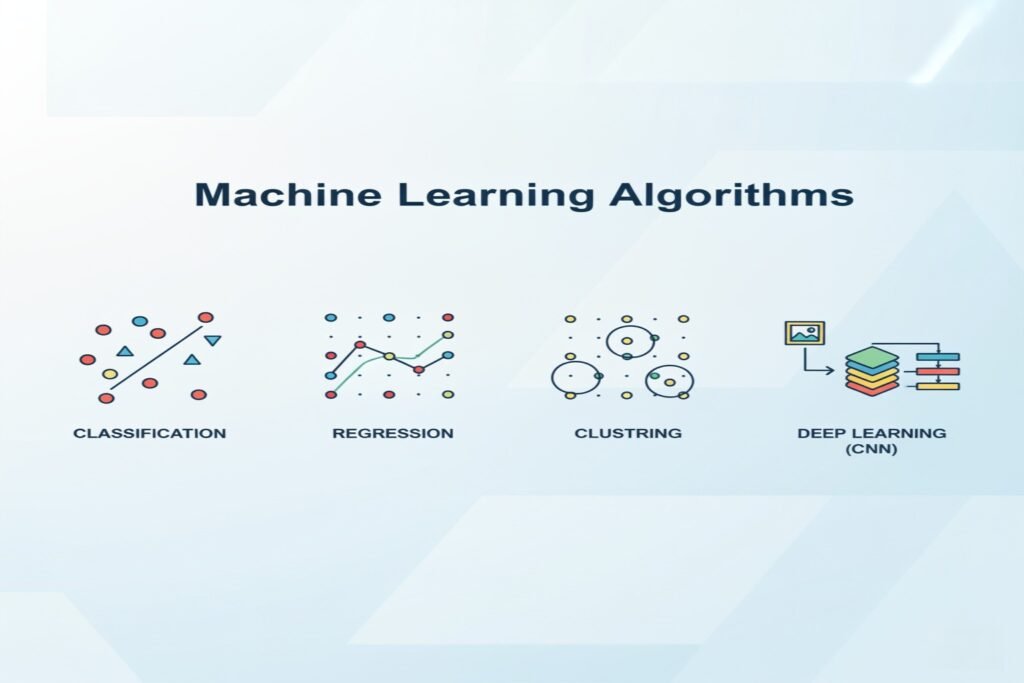
Practical Tip: Start with simple models for baseline performance. Complex models can be explored once you have a solid understanding of the data.
7. Model Training
Training involves feeding the algorithm with data and adjusting its parameters to minimize errors.
Best practices
- Split data into training, validation, and test sets (commonly 70-15-15%)
- Use cross-validation to prevent overfitting
- Monitor training metrics to ensure convergence
Example: For a Random Forest classifier, you might tune n_estimators and max_depth to optimize accuracy and prevent overfitting.
8. Model Evaluation
Once trained, evaluating your model is crucial to understanding its performance in real-world scenarios.
Key metrics
- Classification: Accuracy, Precision, Recall, F1-score, ROC-AUC
- Regression: RMSE, MAE, R²
- Clustering: Silhouette score, Davies-Bouldin index
Example: A churn model might achieve 85% accuracy, but if the recall is low, it could miss most churn cases. Balancing precision and recall is essential.
9. Hyperparameter Tuning
Hyperparameters are model-specific settings that influence learning. Optimizing them improves performance.
Techniques
- Grid Search
- Random Search
- Bayesian Optimization
Example: Tuning max_depth and min_samples_split for a Random Forest can significantly improve predictive performance without overfitting.
10. Model Deployment
Deploying a model turns insights into actionable results. Deployment can be internal (dashboards, alerts) or external (customer-facing applications).
Deployment strategies
- REST APIs (Flask, FastAPI)
- Cloud platforms (AWS SageMaker, GCP AI Platform)
- Edge devices (IoT applications)
Practical Tip: Include monitoring tools to track model performance and detect drift over time.
When building your deployment pipeline, tools like Docker, REST APIs, or serverless endpoints are common. Northflank’s walkthrough is especially useful for understanding step-by-step workflows in real production environments.
11. Model Monitoring and Maintenance
Machine learning models degrade over time due to changing data patterns (concept drift). Continuous monitoring ensures sustained performance.
Monitoring techniques
- Track key metrics (accuracy, error rates)
- Monitor input data distribution
- Schedule periodic retraining
Example: A sales prediction model may need retraining every quarter to incorporate seasonal trends and changing customer behavior.
For bridging your models smoothly into production infrastructure, Pecan’s article on versioning, CI/CD, and automated rollout strategies is a great practical read.
12. Real-World Example: Predicting Hospital Readmissions
Scenario: A healthcare provider wants to predict patient readmissions within 30 days.
Workflow Application
- Problem Definition: Reduce readmissions to improve care quality.
- Data Collection: EMR, patient demographics, prior admissions.
- Data Cleaning: Impute missing lab results, remove duplicates.
- EDA: Identify high-risk conditions correlated with readmissions.
- Feature Engineering: Create features like
days_since_last_visit. - Model Selection: Random Forest for interpretability and performance.
- Training & Evaluation: 5-fold cross-validation, F1-score optimization.
- Hyperparameter Tuning: Grid Search for
max_depthandn_estimators. - Deployment: REST API integrated with hospital dashboard.
- Monitoring: Track model accuracy and patient outcomes monthly.
Key Takeaways
- Structured Workflow: Following a step-by-step machine learning workflow enhances efficiency and reproducibility.
- Data Quality: High-quality data is often more important than complex models.
- Feature Importance: Thoughtful feature engineering can dramatically improve performance.
- Evaluation Metrics: Choose metrics aligned with business objectives.
- Continuous Improvement: Model deployment is just the beginning; monitoring and maintenance are essential.
Conclusion
Understanding the machine learning workflow transforms abstract concepts into actionable solutions. Whether predicting customer churn, forecasting sales, or reducing hospital readmissions, following a structured process ensures clarity, accuracy, and scalability. By investing time in each stage—from problem definition to deployment and monitoring—you not only build robust models but also generate meaningful business or research impact.
Embark on your next machine learning project with a clear workflow in mind, and you’ll turn raw data into actionable insights efficiently and reliably.

