
Introduction
Machine learning has moved far beyond research labs—it now powers fraud detection, recommendation systems, chatbots, and even autonomous vehicles. But behind the hype lies a hard truth: building reliable machine learning models is not easy. Most organizations face machine learning challenges ranging from messy data to ethical dilemmas.
Think about it: if a model misclassifies spam emails, the consequence is mild. But if an autonomous vehicle fails to detect a pedestrian because of poor training data, the result could be catastrophic. This gap between promise and practice makes understanding the hurdles—and their solutions—essential for anyone working with machine learning.
In this blog, we’ll dive into the most pressing machine learning challenges practitioners face today, explore why they matter, and share practical solutions drawn from real-world scenarios.
1. The Data Quality Dilemma
“Garbage in, garbage out” is perhaps the oldest saying in computer science—and it perfectly applies to machine learning.
The Challenge
Most ML projects fail not because of the algorithm but because of the data feeding it. Common issues include:
- Incomplete data: Missing entries (e.g., customer age or transaction details).
- Inconsistent data: Different formats (USD vs. PKR, mm/dd/yyyy vs. dd/mm/yyyy).
- Noisy data: Irrelevant or duplicate features.
In fact, a survey by VentureBeat reported that 80% of a data scientist’s time is spent cleaning and preparing data rather than modeling.
The Solution
- Automated data preprocessing – Use pipelines with tools like Pandas Profiling, Great Expectations, or TensorFlow Data Validation.
- Domain expertise collaboration – Involve subject-matter experts early to validate labels and ensure context is not lost.
- Active learning – Iteratively improve dataset quality by letting models highlight uncertain predictions for human review.
Always maintain a data documentation sheet (also known as a datasheet for datasets) to track source, assumptions, and known biases.
Frameworks like Great Expectations provide automated validation to catch inconsistencies early in the pipeline
2. Dealing with Data Scarcity
The Challenge
Machine learning thrives on big data. But in many domains—like medical imaging or legal document classification—collecting large, labeled datasets is expensive and sometimes impossible. For instance, getting thousands of MRI scans for rare diseases isn’t realistic.
The Solution
- Transfer Learning: Use pre-trained models (like BERT, GPT, or ResNet) and fine-tune them on small datasets.
- Data Augmentation: Generate synthetic variations (rotating medical images, adding noise to audio files).
- Synthetic Data: Tools like Synthea (for healthcare) or Unity (for vision tasks) create artificial yet realistic datasets.
Example: Tesla often uses simulated driving environments to train and stress-test their autonomous vehicle algorithms before exposing them to real roads.
In domains like healthcare, synthetic data tools such as Synthea are helping researchers generate realistic patient records for model training without privacy risks.
3. Bias and Fairness Issues
The Challenge
AI doesn’t just learn patterns—it also inherits the biases in data. In 2020, a study showed facial recognition systems misidentified people with darker skin tones at significantly higher rates. In high-stakes fields like hiring or law enforcement, such bias can lead to discrimination.
The Solution
- Bias detection tools – Libraries like IBM’s AI Fairness 360 or Google’s What-If Tool help audit models.
- Balanced datasets – Ensure demographic representation (gender, ethnicity, geography).
- Explainability methods – Techniques like SHAP or LIME help identify why a model made a certain decision.
Organizations should treat bias audits like security audits: ongoing, systematic, and essential.
4. The “Black Box” Problem
The Challenge
Deep learning models, especially neural networks, often act like black boxes. While they deliver high accuracy, their inner decision-making process is opaque. This lack of interpretability can reduce stakeholder trust.
Imagine a bank’s credit approval system: if the algorithm rejects a loan application, the customer deserves an explanation—not just a numerical score.
The Solution
- Interpretable models: Use decision trees or linear models when transparency is more valuable than accuracy.
- Explainability techniques: Employ SHAP (Shapley Additive Explanations) to attribute feature importance.
- Model monitoring dashboards: Track prediction drift and provide human-readable explanations.
Visual Idea: An infographic comparing “Black Box vs Explainable AI” with examples of industries needing each.
5. Overfitting and Underfitting
The Challenge
Striking the balance between model complexity and generalization is tricky:
- Overfitting: Model memorizes training data, failing to generalize.
- Underfitting: Model is too simplistic, missing important patterns.
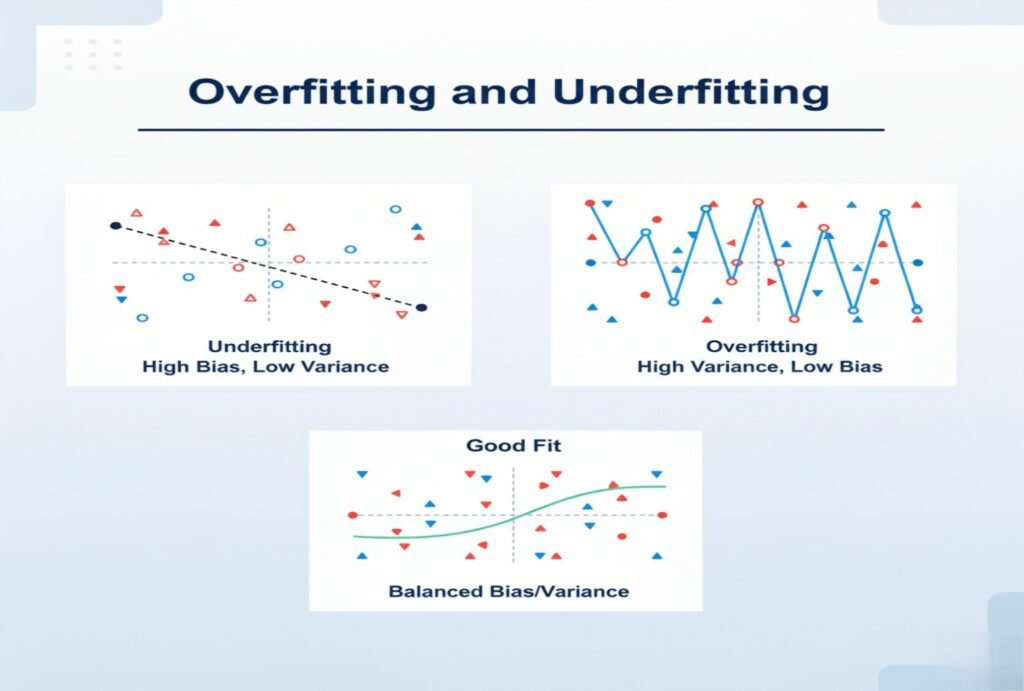
This is one of the most persistent machine learning challenges, especially when data is limited or noisy.
The Solution
- Regularization: Apply L1/L2 penalties to reduce over-complexity.
- Cross-validation: Test models on different subsets of data to ensure generalization.
- Dropout layers: In neural networks, randomly “dropping” neurons during training prevents overfitting.
6. Scaling Machine Learning Models
The Challenge
Training a model on a laptop may work for prototypes, but production-scale systems need distributed processing, storage, and monitoring. Handling terabytes of data or serving predictions to millions of users is no small feat.
The Solution
- MLOps Practices: Adopt CI/CD pipelines for machine learning, using tools like MLflow, Kubeflow, or AWS SageMaker.
- Cloud Infrastructure: Leverage scalable GPUs/TPUs from Google Cloud, AWS, or Azure.
- Monitoring & Retraining: Deploy drift detection to ensure models stay relevant as data changes.
Example: Netflix constantly re-trains its recommendation engine as user behavior evolves. Without scaling pipelines, personalization at their scale would be impossible.
As described in Databricks’ guide on MLOps best practices, writing clean code, selecting the right cluster, and monitoring systems are crucial steps.
7. Ethical and Privacy Concerns
The Challenge
Collecting and processing sensitive user data poses ethical and legal challenges. With stricter regulations like GDPR in Europe and upcoming AI Acts, non-compliance can result in heavy fines.
The official TensorFlow Federated tutorial offers a detailed walkthrough of differential privacy in federated learning.
The Solution
- Privacy-preserving ML: Techniques like federated learning (training models on local devices without centralizing data).
- Differential Privacy: Adding statistical noise to protect individual identities while retaining data patterns.
- Ethics boards & governance: Many companies now establish AI ethics committees to review use cases.
8. Cost and Resource Constraints
The Challenge
Training advanced ML models can be resource-intensive. For instance, training GPT-style models costs millions in compute and energy, making it inaccessible for smaller companies.
The Solution
- Model optimization: Use pruning, quantization, or knowledge distillation to shrink models without losing accuracy.
- Open-source alternatives: Lightweight models like DistilBERT or EfficientNet are cost-friendly substitutes.
- Hybrid approaches: Offload heavy computations to the cloud while using local devices for lightweight inference.
Comparative Snapshot
Here’s a quick comparison of common machine learning challenges and practical solutions:
| Challenge | Solution |
| Data Quality Issues | Preprocessing pipelines, active learning, documentation |
| Data Scarcity | Bias audits, balanced datasets, and explainability tools |
| Bias & Fairness | Bias audits, balanced datasets, explainability tools |
| Black Box Models | Interpretable algorithms, SHAP/LIME, monitoring dashboards |
| Over/Underfitting | Regularization, cross-validation, dropout |
| Scaling ML | MLOps, cloud infrastructure, retraining pipelines |
| Ethics & Privacy | Federated learning, differential privacy, ethics boards |
| Cost Constraints | Transfer learning, augmentation, and synthetic data |
Key Takeaways
- Data quality is king—no algorithm can fix fundamentally flawed data.
- Bias is everyone’s problem—unchecked bias leads to unethical AI.
- Explainability builds trust—especially in regulated industries.
- Scaling isn’t just technical—it requires organizational readiness and MLOps maturity.
- Privacy-first ML will shape the future of AI adoption.
Conclusion
Machine learning is powerful, but the road to reliable solutions is filled with obstacles. From dirty data to ethical dilemmas, every stage of the pipeline presents unique challenges. The good news? With the right tools, strategies, and mindset, these hurdles can be overcome.
As businesses and researchers continue to push AI boundaries, acknowledging and addressing these machine learning challenges is not just a technical requirement—it’s a responsibility.

