
Introduction: Machine Learning
Have you ever wondered how Netflix seems to read your mind, suggesting the perfect show for a Friday night? Or how your email spam filter tirelessly guards your inbox from a barrage of “special offers” and “urgent requests”? The invisible hand behind these modern conveniences is machine learning (ML), a transformative technology that’s less about futuristic robots and more about teaching computers to learn from experience. If you’ve ever felt curious about how it all works but found explanations filled with impenetrable jargon, you’re in the right place. This guide will demystify the machine learning basics, not with dry textbooks, but with relatable stories, clear examples, and a practical path forward. Let’s pull back the curtain.
What Is Machine Learning, Really?
Let’s start with a simple definition. At its core, machine learning is a subset of artificial intelligence (AI) that enables computers to learn from data without being explicitly programmed for every single task.
Think of it this way:
- Traditional Programming: You write strict rules. “If a user clicks X, then open Y.” The computer follows your instructions to the letter.
- Machine Learning: You show the computer examples. You feed it thousands of pictures labeled “cat” and “not cat.” The computer discovers its own patterns and writes its own rules to identify future cats.
It’s the difference between teaching a child to read by drilling them on every word versus giving them books and letting their brain decipher the patterns of language. ML systems learn through a continuous, iterative process of finding patterns in data, making decisions based on those patterns, and then improving as they receive more data.
Why Machine Learning is a Game-Changer?
The power of ML isn’t just in cool tech demos; it’s reshaping our world. Its ability to find hidden insights in vast, complex datasets makes it indispensable across industries. Consider these applications:
- Healthcare: Algorithms can now analyze medical images to detect diseases like diabetic retinopathy or certain cancers with accuracy rivaling human experts, enabling earlier and more accessible diagnostics.
- Finance: ML models scrutinize millions of transactions in real-time to spot fraudulent activity, protecting consumers and saving institutions billions.
- E-commerce & Entertainment: The recommendation engines at Amazon, Spotify, and Netflix aren’t just guessing. They’re sophisticated ML systems that analyze your behavior, compare it to millions of other users, and predict what you might want next, creating a deeply personalized experience.
A report from McKinsey & Company found that 56% of all companies have adopted AI/ML in at least one function, a number that continues to grow rapidly. This isn’t a niche skill; it’s becoming a fundamental literacy in the digital age.
How Machine Learning Works: The Engine Under the Hood
Understanding the basic workflow is crucial to moving from mystery to mastery. Most ML projects follow a structured pipeline:
- Data Collection: This is the foundation. Everything starts with data—lots of it. This could be user purchase history, sensor readings from a factory, satellite images, or text from social media posts.
- Data Preparation & Cleaning: Raw data is messy. This stage involves handling missing values, correcting errors, and converting data into a format the algorithms can understand. This is often the most time-consuming part of a data scientist’s job, but arguably the most important.
- Model Training: This is where the magic happens. You select an algorithm (e.g., a decision tree, a neural network) and “feed” it your prepared data. The algorithm iteratively adjusts its internal parameters to minimize errors and improve its predictions. It’s like tuning a radio dial to get the clearest signal.
- Evaluation: How good is your tuned model? You test it on a separate set of data that it has never seen before (called the testing set) to see how well it generalizes. This prevents the model from simply “memorizing” the answers, a problem known as overfitting.
- Prediction: Once you’re satisfied with the model’s performance, you deploy it into a real application to make predictions or decisions on new, unseen data.
The Three Flavors of Learning: Supervised, Unsupervised, and Reinforcement
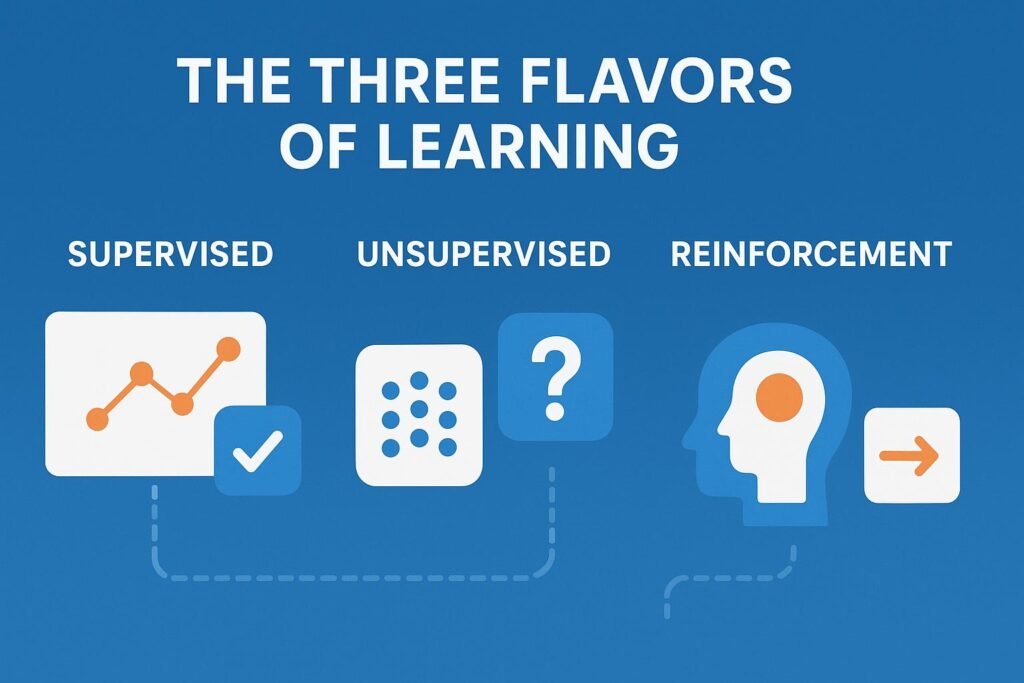
ML isn’t a monolith. How a model learns depends on the data and the problem, leading to three primary categories:
| Type | How It Learns | Real-World Analogy | Common Use Cases |
| Supervised Learning | From labeled data (data with known answers). | A student learning with flashcards that have questions on one side and answers on the other. | Spam filtering, weather forecasting, price prediction. |
| Unsupervised Learning | From unlabeled data, finding hidden structures. | Giving a kid a pile of Legos and letting them sort them by color and shape on their own. | Customer segmentation, anomaly detection (e.g., credit card fraud), gene sequencing. |
| Reinforcement Learning | Through trial and error, receiving rewards for good actions. | Through trial and error, one receives rewards for good actions. | Teaching a dog a new trick, it tries behaviors and gets a treat for the correct ones. |
A Personal Insight: When I first started, I struggled to remember the difference. I finally clicked when I framed it as answers provided (Supervised), find the pattern yourself (Unsupervised), and learn by doing (Reinforcement).
Your Hands-On Roadmap to Getting Started
Theory is essential, but ML is a practical field. The best way to learn is by doing. Here’s a beginner-friendly roadmap to launch your journey.
Step 1: Build Your Foundation
You don’t need a PhD in mathematics to start, but a few basics will make your life easier:
- Basic Statistics & Probability: Concepts like mean, median, standard deviation, and correlation help you understand and describe your data.
- Programming: Python is the undisputed king of ML for beginners. It’s readable, has a huge community, and most importantly, boasts incredible libraries.
Step 2: Get Comfortable with Key Python Libraries
You don’t need to build everything from scratch. These libraries are your best friends:
- Pandas: For data manipulation and analysis. Think of it as a super-powered Excel spreadsheet inside Python.
- NumPy: The foundation for scientific computing. It provides support for large, multi-dimensional arrays and matrices.
- Scikit-learn: The go-to library for classical ML algorithms. It has clean, consistent tools for everything from regression to clustering.
- Matplotlib/Seaborn: For creating static, animated, and interactive visualizations to explore your data.
Step 3: Tackle a “Hello, World!” Project
The Titanic dataset on Kaggle is the quintessential first project. The goal is simple: use passenger data (like age, gender, and ticket class) to predict who survived. It teaches you the entire ML pipeline in a single, compelling problem.
Beyond the basics: Once you’re comfortable, try something like:
- Sentiment Analysis: Scrape Twitter API data to classify tweets about a topic as positive, negative, or neutral.
- Image Classification: Use a pre-built model to identify different breeds of cats and dogs.
Platforms like Kaggle and Google Colab provide free datasets, code examples, and even cloud-based notebooks to run your code, removing all setup friction.
Navigating Common Hurdles and Ethical Considerations
The path isn’t always smooth. Being aware of challenges is part of the learning process.
- The Data Quality Problem: Your model is only as good as your data. Biased, incomplete, or inaccurate data will lead to flawed and potentially harmful outcomes. A famous example is an HR recruitment tool that was scrapped because it learned to discriminate against women, having been trained on historical data from a male-dominated industry.
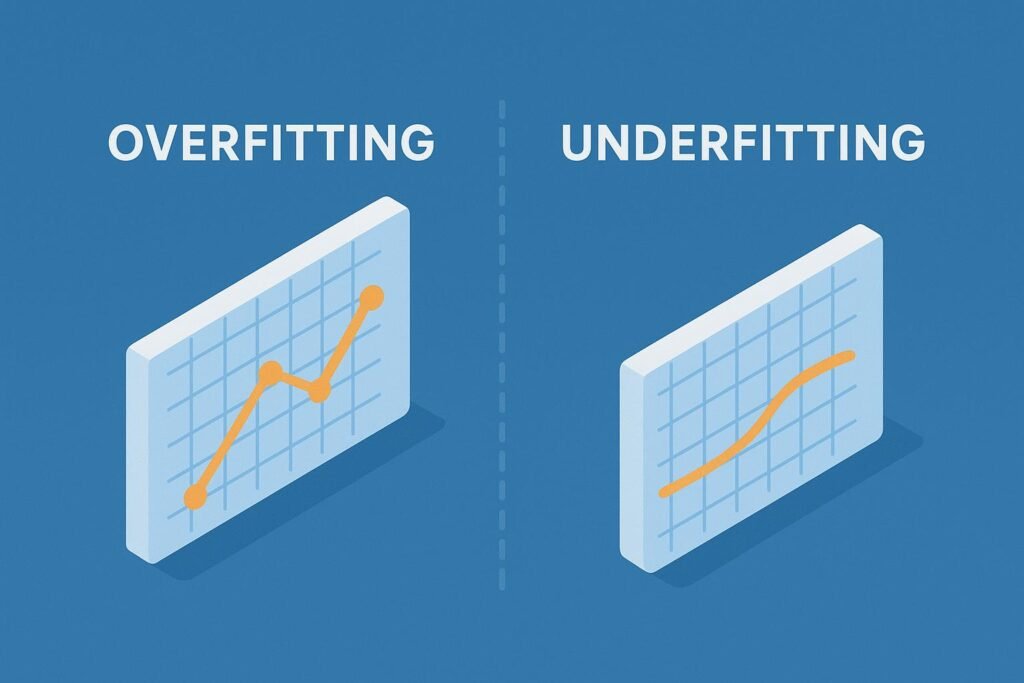
- Overfitting vs. Underfitting: This is the Goldilocks problem of ML.
- Overfitting: The model learns the training data too well, including its noise and outliers. It performs perfectly on the data it saw, but fails on new data. It’s like memorizing the answers to a practice test but failing the real exam because the questions are worded differently.
- Underfitting: The model is too simple to capture the underlying trend in the data. It performs poorly on both seen and new data.
- The Solution: Techniques like cross-validation (rigorously testing on held-out data) and regularization (simplifying the model) help find the “just right” balance.
The Future is Learning
Machine learning is not a static field. We’re moving into an era of AutoML (automating the process of applying ML) and grappling with the critical importance of Explainable AI (XAI)—making the “black box” decisions of complex models understandable to humans. As ML becomes more integrated into our lives, the conversation around ethics, bias, and transparency will only grow louder and more critical.
Conclusion: Your Journey Begins Now
Understanding machine learning basics is your first step into a larger world. It’s a field of immense creativity and impact, where you can teach computers to see, listen, and predict. It might seem daunting, but every expert was once a beginner who decided to build their first model.
The most important step is the first one. Pick a small project, embrace the messiness of data, and start learning by doing.
Related Articles
- How Machine Learning Differs from AI?
- Types of Machine Learning Explained: A Complete Guide
- Key Machine Learning Algorithms for Beginners
- Machine Learning Use Cases Across Industries
- How Machine Learning Transforms Business Strategy
- Essential Tools for Machine Learning Projects
- A Step-by-Step Machine Learning Workflow
- Common Machine Learning Challenges and Solutions
- Machine Learning Best Practices for Success
- How to Start a Career in Machine Learning: A Complete Roadmap

