
Introduction: Why Best Practices Matter in Machine Learning
Imagine pouring weeks into training a machine learning model, only to discover it fails miserably when tested in real-world conditions. Frustrating, right? This is a common scenario for many businesses and data teams. The truth is, machine learning is not just about writing algorithms — it’s about designing systems that work reliably, scale efficiently, and deliver measurable value. That’s where machine learning best practices come into play. By following proven principles, teams can avoid pitfalls such as overfitting, data leakage, poor scalability, or lack of stakeholder alignment. Whether you’re a data scientist, ML engineer, or business leader, adopting these practices can dramatically increase the chances of your project’s success.
In this article, we’ll explore practical, research-backed, and experience-driven best practices for machine learning success. We’ll go beyond generic advice and dive into real-world insights, comparisons, and actionable takeaways.
1. Start with the Problem, Not the Algorithm
One of the most common mistakes in machine learning projects is jumping straight into model development. It’s tempting to experiment with deep learning architectures or fancy algorithms, but success begins with understanding the problem deeply.
Ask yourself:
- What business or real-world problem are we solving?
- How will success be measured (KPIs, metrics, ROI)?
- Do we even need machine learning, or can a simpler rule-based system work?
Example: A retail company wants to reduce customer churn. Instead of building a complex neural network right away, the team could start by defining churn clearly (e.g., “no purchases in 90 days”) and exploring simple predictive models like logistic regression before scaling up.
Best Practice: Always align technical work with a well-defined business or research objective.
2. Data Quality Over Data Quantity
“Garbage in, garbage out” holds true more than ever in machine learning. A sophisticated model trained on poor-quality data will underperform.
Key steps for ensuring data quality
- Data Cleaning: Handle missing values, duplicates, and inconsistent labels.
- Bias Mitigation: Check for sampling bias — does your dataset represent the real-world distribution?
- Feature Engineering: Transform raw data into meaningful variables (e.g., transaction frequency instead of raw timestamps).
- Annotation Consistency: In supervised learning, inconsistent labeling can destroy accuracy.
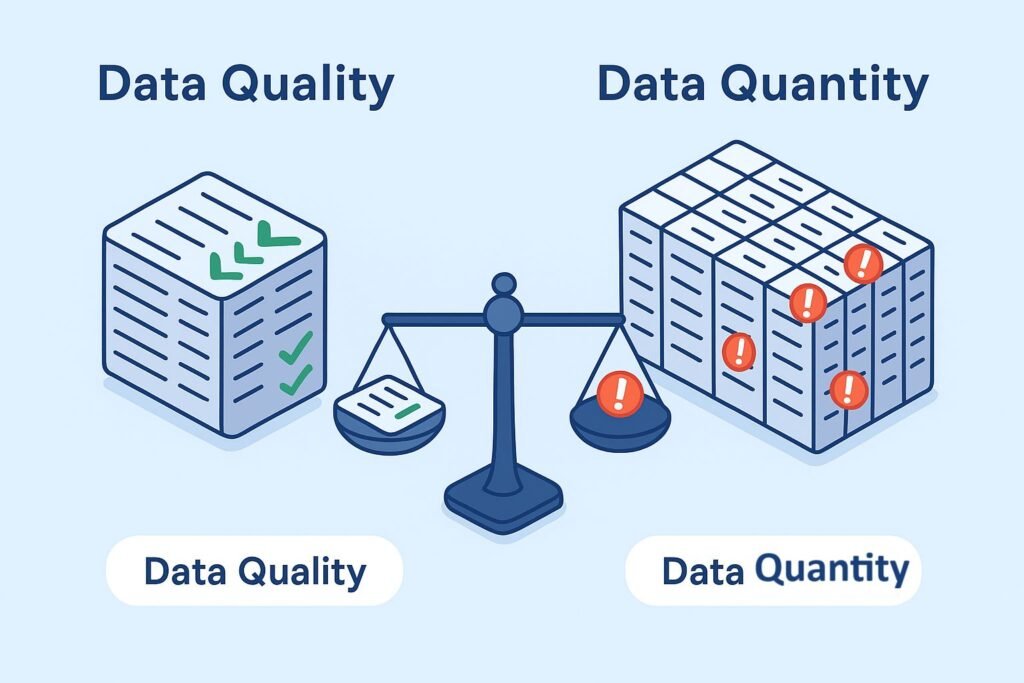
Quick Comparison: Data Quality vs. Data Quantity
| Aspect | High Quality, Low Quantity | Low Quality, High Quantity |
|---|---|---|
| Accuracy | Often high (if representative) | Poor, even with more data |
| Generalization | Strong, less overfitting risk | Weak, prone to errors |
| Scalability | Easier to scale later | Requires massive cleaning |
Best Practice: Invest early in data validation pipelines, not just bigger datasets.
3. Choose the Right Metrics
Accuracy is not always the best measure of success. Depending on the problem, different metrics matter.
- Imbalanced datasets: Use F1-score, Precision, Recall, or AUC-ROC.
- Regression problems: Use RMSE, MAE, or R².
- Business-focused tasks: Use cost-sensitive metrics (e.g., false negatives in fraud detection are far costlier than false positives).
Scenario: In fraud detection, a model with 99% accuracy might look impressive. But if only 1% of transactions are fraudulent, the model could simply predict “no fraud” every time and still achieve 99%. That’s useless in practice.
Best Practice: Select metrics aligned with business objectives and data distribution.
4. Avoid Overfitting and Underfitting
Overfitting happens when a model memorizes training data but fails on unseen data. Underfitting occurs when the model is too simple to capture underlying patterns.
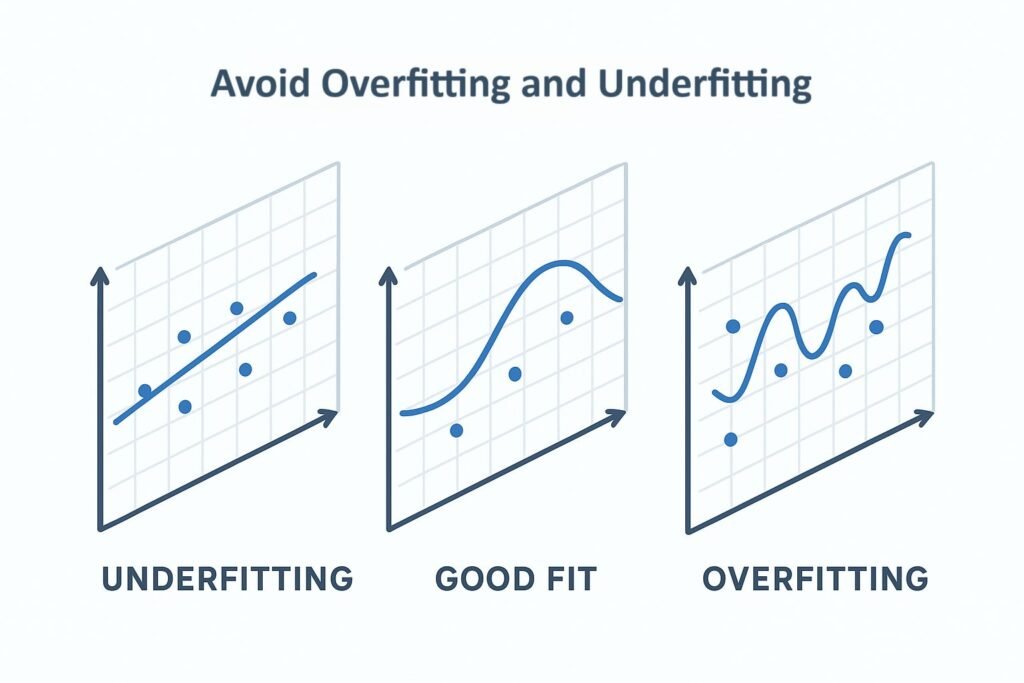
Strategies to prevent overfitting
- Cross-validation (k-fold, stratified sampling)
- Regularization (L1, L2)
- Dropout in neural networks
- Early stopping during training
- Increasing training data diversity
Best Practice: Always evaluate models on validation and test sets before deployment.
5. Prioritize Explainability and Transparency
As machine learning models grow more complex, stakeholders often ask: “Why did the model make this prediction?”
Techniques like SHAP values, LIME, or feature importance rankings can help explain decisions. Explainability is critical in domains like healthcare, finance, and law, where trust and compliance matter.
Example: A bank rejecting a loan application must explain why. If the model only outputs “Rejected,” customers and regulators won’t accept it. Feature importance (e.g., income stability, repayment history) provides transparency.
Best Practice: Incorporate explainability tools into your ML pipeline from the start, not as an afterthought.
6. Build for Scalability and Deployment Early
Many ML projects fail not because of poor models, but because they can’t be deployed or scaled effectively.
Treat ML projects as end-to-end systems, not just isolated models. A detailed Google MLOps best practices guide explains how automation and CI/CD pipelines ensure smooth deployment.
Best practices for deployment-ready ML
- Modular Pipelines: Separate data ingestion, training, evaluation, and deployment.
- MLOps Practices: Use tools like MLflow, Kubeflow, or Vertex AI for versioning, monitoring, and automation.
- API Integration: Expose models via APIs for easy integration with business systems.
- Monitoring in Production: Continuously track performance, drift, and latency.
Best Practice: Treat ML projects as end-to-end systems, not just isolated models.
7. Monitor Model Drift and Retrain Regularly
The world changes, and so does data. A model trained last year may fail today due to concept drift or data drift.
- Data Drift: Input data distribution changes (e.g., customer demographics).
- Concept Drift: Relationship between input and output changes (e.g., fraud patterns evolve).
Example: A recommendation engine trained before COVID-19 would fail when shopping behaviors drastically shifted.
Best Practice: Establish retraining schedules and monitoring systems to catch drift early.
8. Collaborate Across Teams
Machine learning success is not just about data scientists. It requires collaboration across engineers, domain experts, product managers, and business leaders.
- Data scientists bring technical expertise.
- Domain experts ensure problem relevance.
- Engineers handle integration and scalability.
- Business leaders align outcomes with strategy.
Best Practice: Encourage cross-functional communication to bridge the gap between models and business value.
9. Ethical AI and Responsible Practices
Ignoring ethics can backfire — damaging brand trust, leading to lawsuits, or reinforcing harmful biases.
Ethical best practices:
- Audit datasets for biases.
- Ensure fairness across demographics.
- Follow regulations (GDPR, CCPA, AI Act).
- Use anonymization and differential privacy where needed.
Example: A hiring algorithm that favors certain genders or ethnicities can lead to discrimination lawsuits.
Best Practice: Make ethical AI a non-negotiable part of your workflow.
10. Continuous Learning and Experimentation
The ML field evolves rapidly. Techniques that were state-of-the-art last year may be outdated today.
- Stay updated with research papers (arXiv, NeurIPS, ICML).
- Experiment with new architectures and frameworks.
- Encourage a culture of learning within teams.
Best Practice: Treat ML as a living process, not a one-time project.
Key Takeaways
- Understand the problem first before selecting algorithms.
- Data quality matters more than sheer volume.
- Use appropriate metrics tailored to your task.
- Deploy with scalability, monitoring, and explainability in mind.
- Retrain and adapt to real-world changes.
- Promote ethics and collaboration across teams.
Conclusion: Setting the Stage for Long-Term Success
Machine learning is powerful, but success requires more than algorithms. By following these machine learning best practices, you can avoid costly mistakes, build models that scale, and deliver real business value.
The future of ML belongs to teams that not only innovate but also execute responsibly, transparently, and strategically.

